Удаленное тестирование
Отключение контроллеров NetApp FAS8040
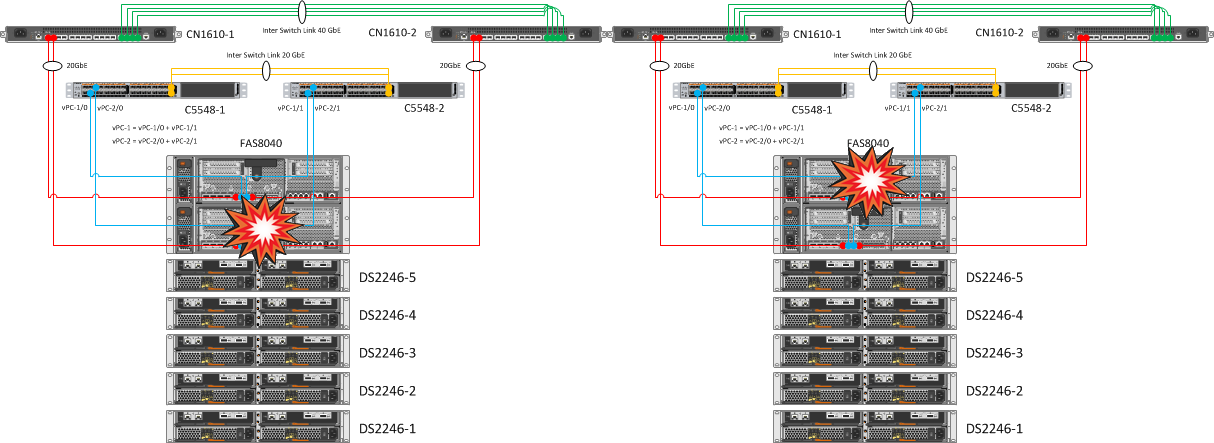
Ожидание: контроллеры будем отключать по очереди, после отключения должно произойти автоматическое переключение на рабочую ноду, сохранится доступность ресурсов VSM на ESXi, доступ к хранилищам останется стабильным.
В итоге: Автоматически переключилась сначала одна, а затем и потом и вторая нода. При отключении одного контроллера его тома без проблем перешли на второй. Весь процесс длился меньше минуты.
Отключение ISL между свичами
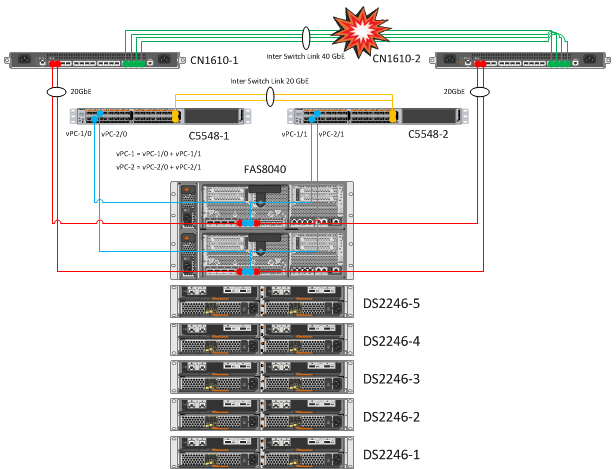
Ожидание: даже если все линки между CN1610 будут загашены, связь между нодами не пострадает.
В итоге: отключение никак не повлияло на связь хоста и сети, для доступа к ESXi использовался второй линк.
Перезагрузка кластерных свичей и Cisco Nexus
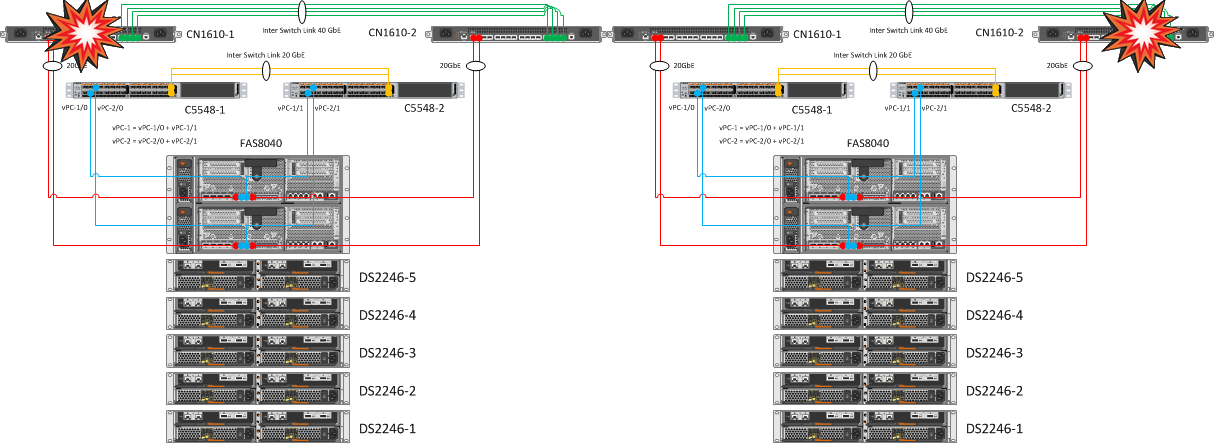
Ожидание: перезагружать свичи будем по одному из пары. Наши действия не должны никак повлиять на работу кластера NetApp. По крайней мере один порт на узлах должен быть доступен, на интерфейсах IFGRP всех нод один из интерфейсов 10 GbE останется в доступе, все ресурсы VSM должны быть доступны на ESXi, доступ к датасторам не пострадает.
В итоге: благодаря второму свичу CN1610 кластер контроллеров сохраняет свою целостность. Отключение одного CN1610 не оказывает никакого негативного влияния, перезагрузка Cisco Nexus прошла совершенно безболезненно за счет дублирования и объединения линков в Port Channels.
Выключение одного из Virtual PortChannel на коммутаторе Cisco Nexus
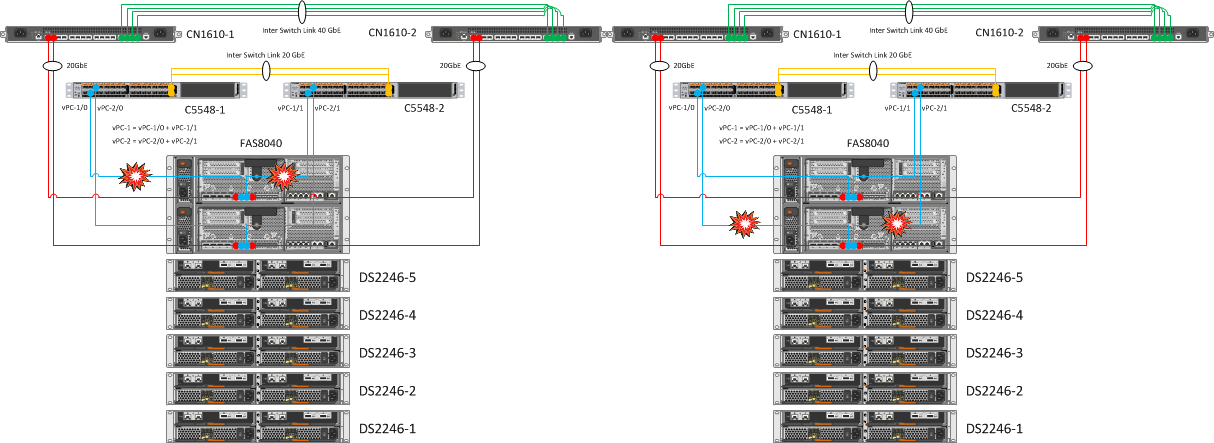
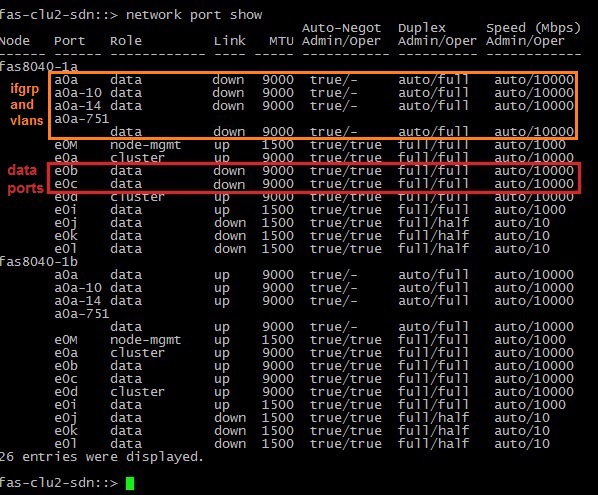
Ожидание: фактически этими действиями мы моделируем сбой, при котором на одной из нод NetApp происходит потеря сетевых линков — в такой ситуации все управление должно перейти на другую ноду.
В итоге: после того, как e0b и e0c интерфейсы, в даун ушли IFGRP a0a и VLAN на ней. Затем просто повторилась ситуация, с которой мы столкнулись на первом шаге тестирования — автоматический тейковер ноды.
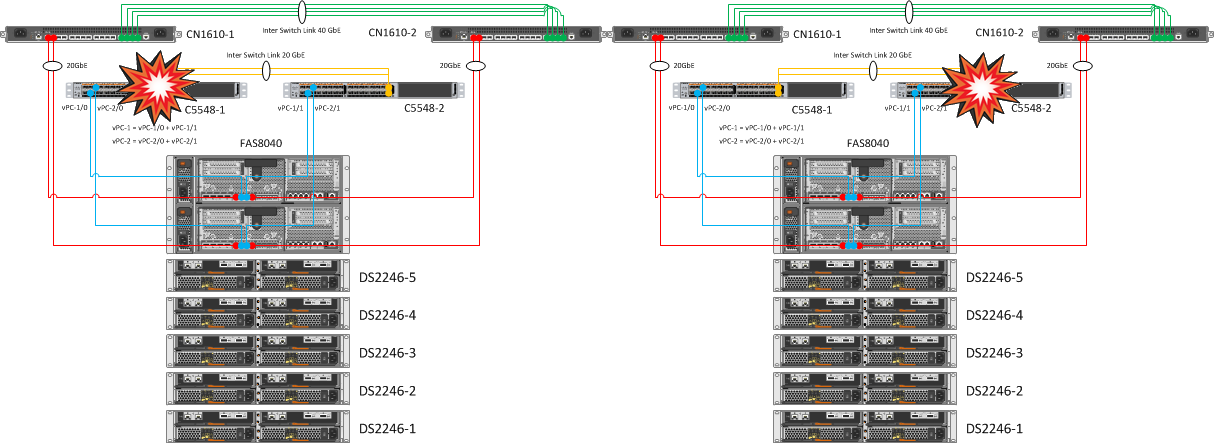
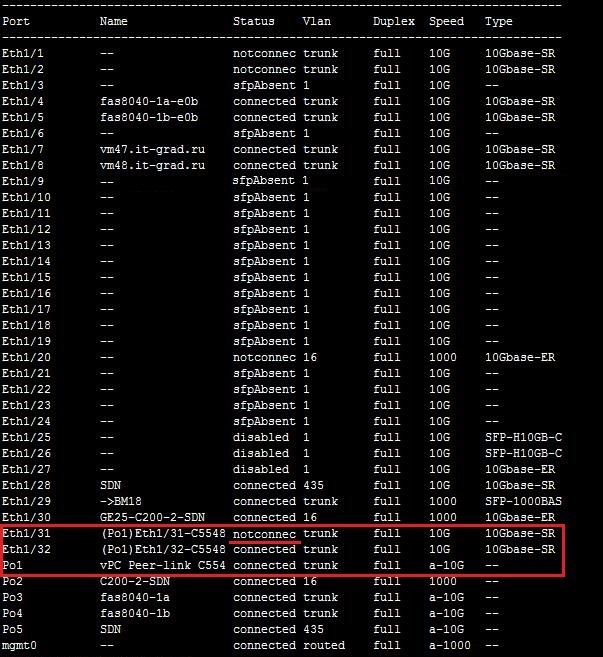
Отключение ISL между коммутаторами Cisco Nexus
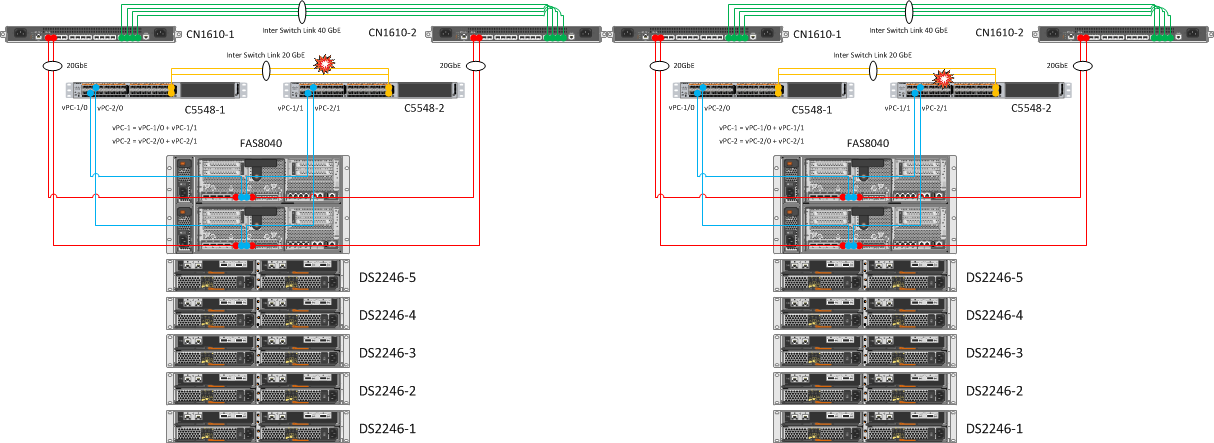
Ожидание: в результате поочередного отключения связность между Nexus’ами не должна пострадать.
В итоге: Eth1/31 и Eth1/32 агрегированы в PortChannel. Когда один из линков между коммутаторами падает, агрегация каналов не позволяет потерять связность между коммутаторами.
Горячее отключение рабочих ESXi-хостов
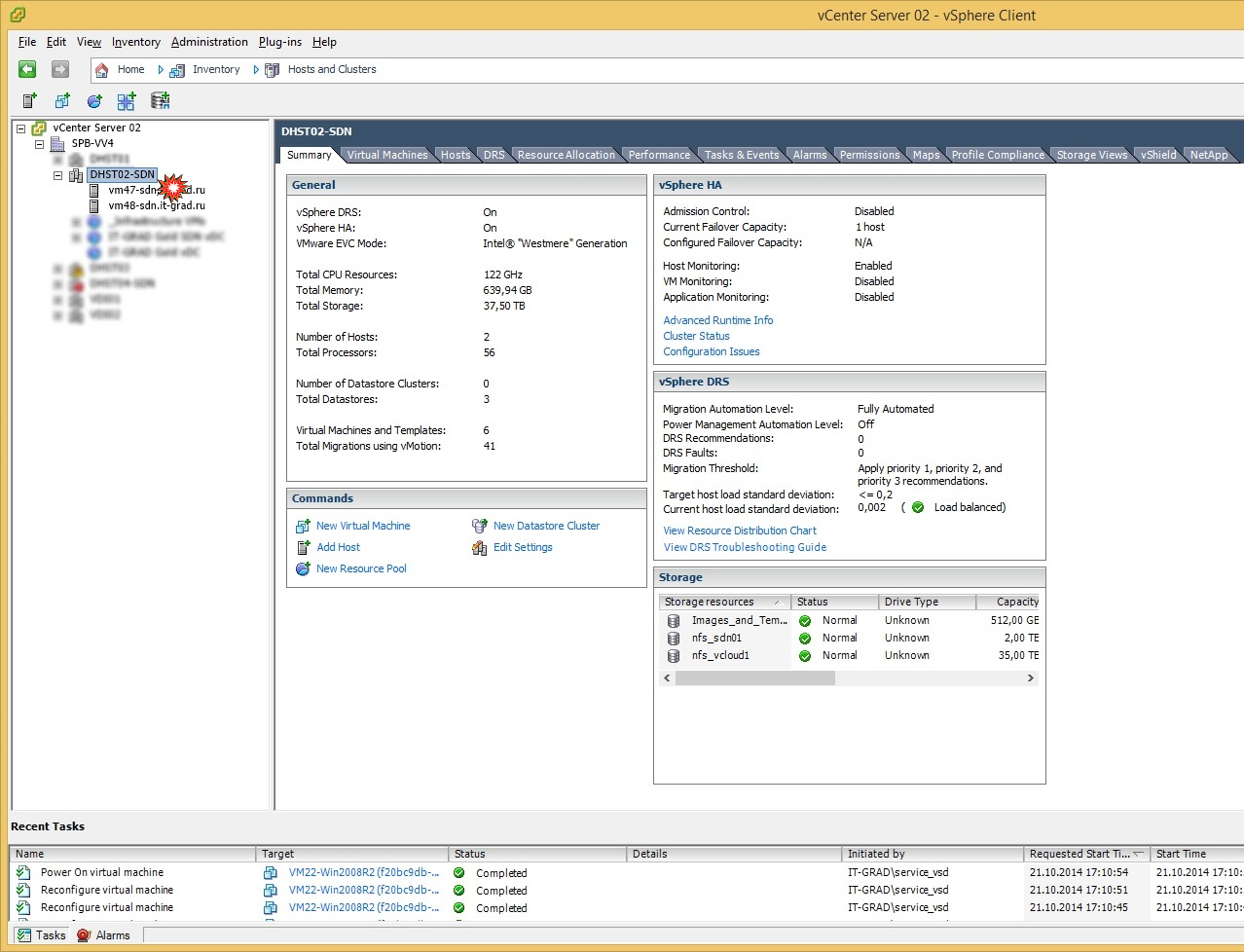
Ожидание: моделируем падение рабочего ESXi-хоста, на котором в момент отключения работало несколько ВМ с разными операционными системами. В идеальной ситуации после падения хоста все машины с него должны перезапуститься на рабочем ESXi-хосте.
В итоге: после отключения одного из хостов отработал VMware High , и все виртуальные машины перешли на рабочий хост. Процесс занял около 5 минут.
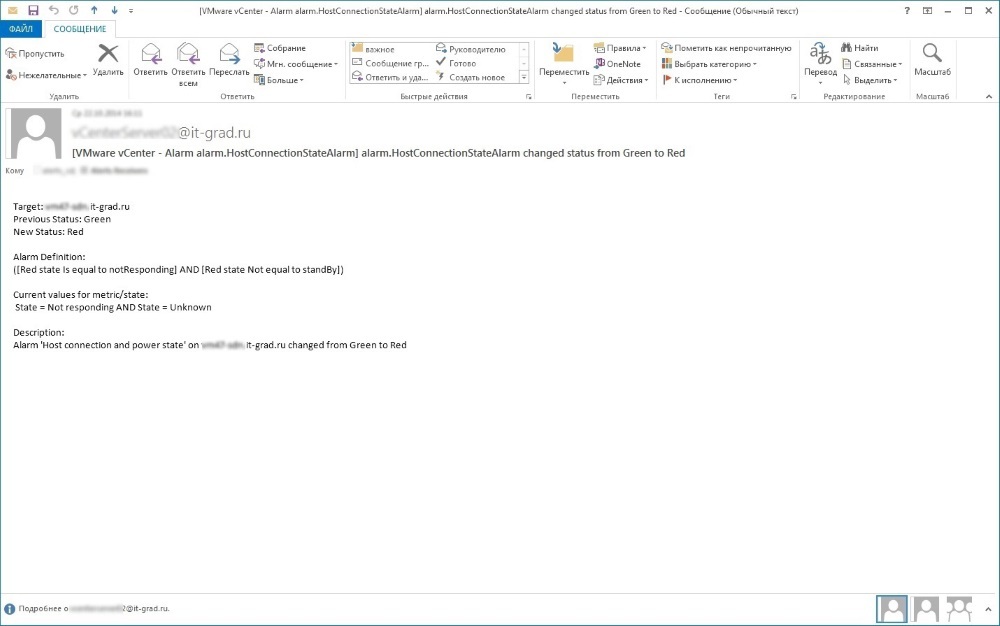
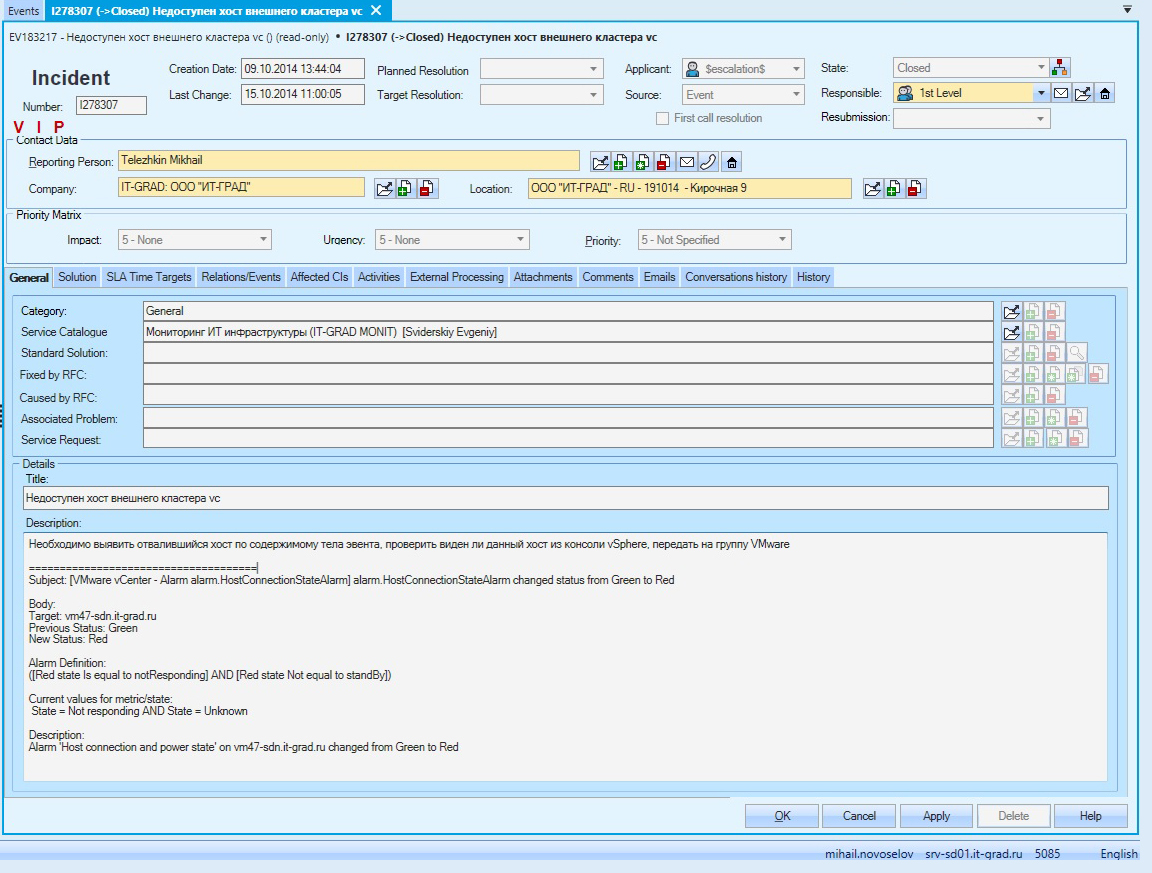
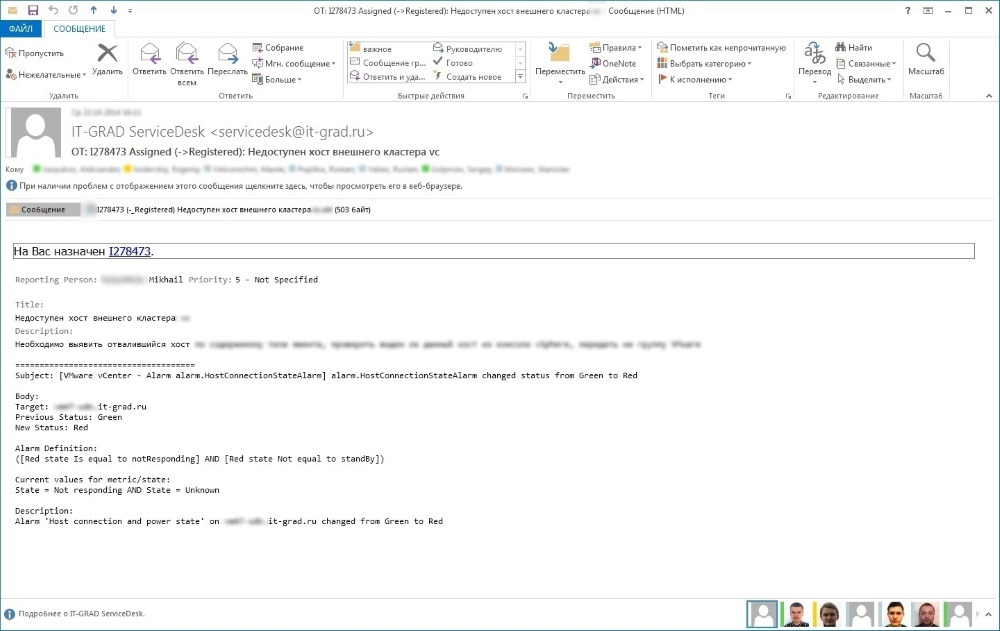
Тестирование отработки системы мониторинга
Ожидание: в результате проведения тестов над мониторингом предполагаем закономерный исход — поток сообщений об ошибках.
В итоге: получение огромного количества ошибок и предупреждений. Система мониторинга активно посылала сообщения в Service Desk, а ITSM-система анализировала эти сообщения по шаблонам и генерировала события. Одинаковые события автоматически собирались в инциденты.
Тестирование непосредственно на стороне аппаратного комплекса

Ожидание: отключаем кабели на всех единых оборудования — они должны продолжить работу от второго блока питания, проблем при переключении между блоками возникнуть не предполагается.
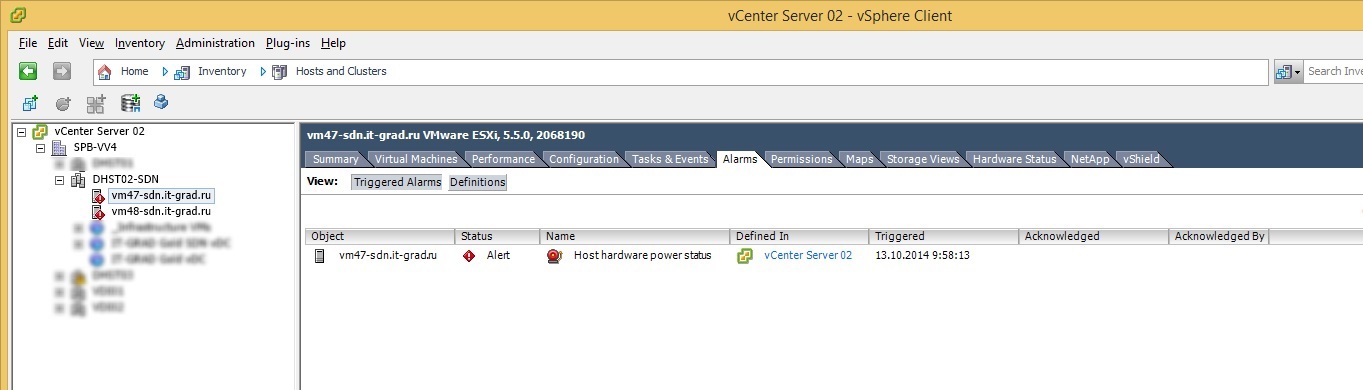
В итоге: NetApp “доложил” и о себе, и о Interconnect свичах. Ошибки хостов ожидаемо появились в vSphere. Ни одна единица оборудования не пострадала в результате отключения кабелей питания.
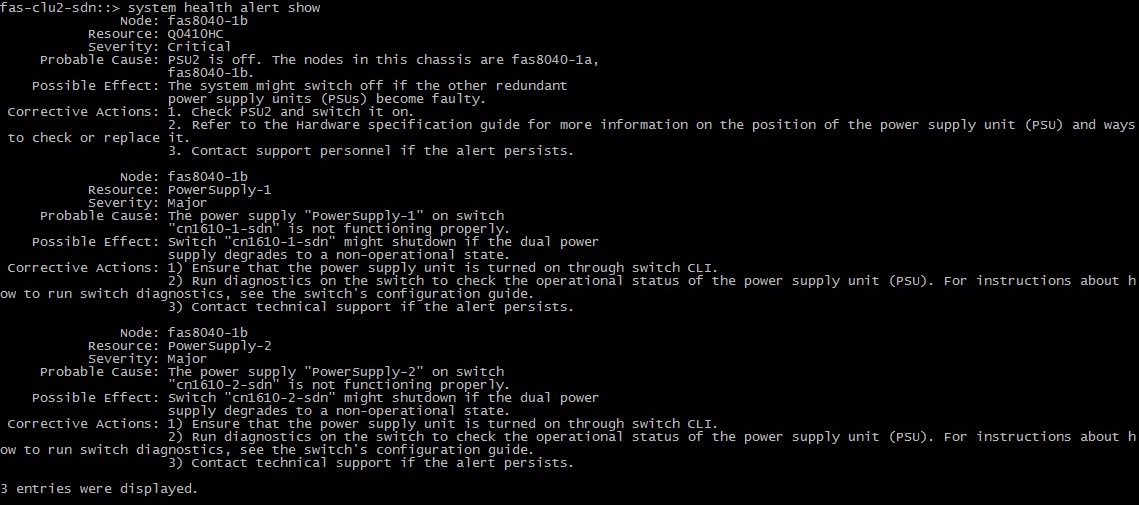
На Clusternet свиче:
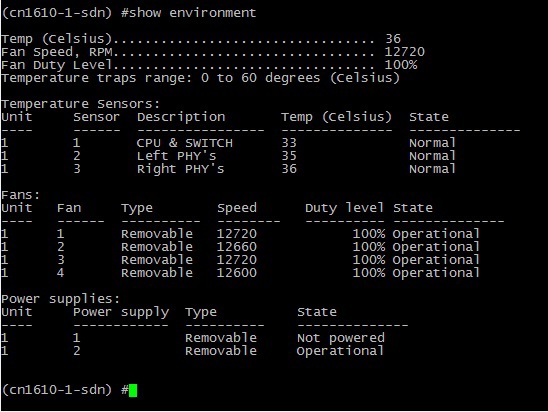
Ошибки в vSphere:
Поочередное отключение сетевых линков от ESXi
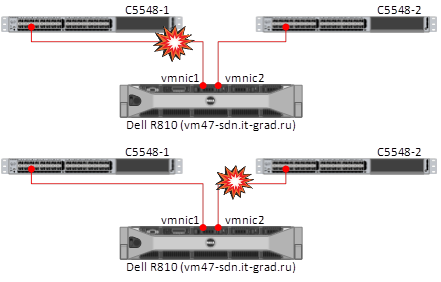
Ожидание: при отключении одного сетевого линка ESXi должен оставаться доступен по второму.
В итоге: ситуация полностью соответствует ожиданиям. Отключение сетевого линка не нарушило коннект между хостом и датастором, ESXi остался доступен по второму линку.
Все испытания пройдены! Результаты тестирования прямо говорят о том, что оборудование подключено, смонтировано и настроено правильно, облачная платформа готова к развертыванию виртуальной инфраструктуры для клиентов. Читатели статьи могут взять вышеприведенные тесты для проведения собственных испытаний.


