Посмотрим, какие есть варианты организации катастрофоустойчивого решения с использованием облаков.
Часто катастрофоустойчивое решение (Disaster Recovery Solution) путают с обычной системой высокой доступности. Оба подхода обеспечивают работоспособность приложения в случае проблем с оборудованием или ПО. Но ключевое отличие в допустимом масштабе аварии. К примеру, у вас может быть отличный 16-узловой HA-кластер, но он никак не спасет от затопления помещения или не слишком прямых рук электрика. В то же время DRS-системы могут выжить при масштабном отказе сразу нескольких дата-центров, не парализуя при этом работу приложения на неопределенный срок.
DRS — это такое программно-апаратно-организационное решение, которое обеспечит доступность критичных систем компании в случае крупных распределенных аварий.
Говоря о системах подобного класса, мы обычно подразумеваем резервный ЦОД, который можно использовать для переноса нагрузки из уже неработающего места. Такие «запасные» дата-центры обычно делят на три типа: холодный, теплый и горячий резерв. Разница более-менее улавливается из названия, но на всякий случай приведу сравнительную табличку:
| Холодный резерв | Теплый резерв | Горячий резерв | |
| Наличие серверов | Нет. Заказываются на складах или перевозятся при аварии | Более слабые серверы в минимально необходимом количестве для старта критичных систем | Да. В полном составе и практически идентично площадке-источнику |
| Подключены ли каналы связи | Да. Но их активация (зачастую и оплата тоже) происходит по факту переезда | Подключены и активированы, всегда готовы к переводу нагрузки | Подключены и активированы, всегда готовы к переводу нагрузки |
| Наличие актуальных данных | Нет. При необходимости информацию привозят (на лентах и дисках) или передают по Сети | Организован регулярный подвоз актуальных данных или копирование/репликация | Да. Синхронная или асинхронная репликация на регулярной основе |
| Соответствие производительности основной площадки | Обычно производительность значительно ниже оригинала. Это обусловлено экономией и отсутствием оборудования | Несколько ниже оригинального дата-центра; не все оборудование может быть на месте | Соответствует для всех важных систем |
| Скорость активации | Может занимать дни и недели, так как многое зависит от поставщиков, транспорта и навыков персонала | В пределах часов-дня, так как все необходимое уже на месте и нужно лишь собрать «мозаику» | Минуты-час, так как есть готовая инфраструктура, каналы, ПО и данные — все это собирается воедино автоматически |
Именно теплый вариант сейчас используется многими компаниями из-за приемлемой стоимости и неплохих временных показателей. Но если задействовать резервную площадку на базе IaaS, то можно получить даже горячий вариант без значительного увеличения бюджета. Давайте рассмотрим такой вариант.
Катастрофоустойчивое решение (DRS) в облачной инфраструктуре идейно не особенно отличается от того, что недавно внедрялось для физической серверной. Просто часть проблем отпала сама собой, и появились некоторые новые возможности. Вообще я бы сравнил DRS в облачной среде со строительными кубиками: выбираешь десяток нужных и складываешь по-разному, пока не получится слово «счастье».
 в облачной инфраструктуре")
В облачном варианте DRS отличается от «олдскульного» подхода следующими моментами:
- Практически отпала необходимость в специфичном железе — виртуальные системы любой сложности строятся из типовых «кубиков». Например, десяток «блейдов» может быть фермой веб-серверов, виртуальным кластером или отказоустойчивой СХД.
- Проще строить высокодоступные решения. Если раньше для организации реплики LUN требовались совместимые СХД со специальными лицензиями, то сейчас достаточно поставить пару галок в виртуальной среде (тот же vSphere vSAN).
- Популярный вектор на аутсорсинг и облачные вычисления позволяет отдать в третьи руки некоторые корпоративные сервисы. Заодно избавиться от необходимости содержать в штате узкоспециализированных сотрудников и строить собственную систему управления и мониторинга.
- Как следствие всего этого — сильно снижается стоимость DR-решения. Благодаря подходу «плати по потребности», организация географически удаленной площадки вполне вписывается в бюджет средней российской компании.
Всевозможные плюсы и новизна — это хорошо, но за ними должна стоять практичность, чтобы не получилось «технологии ради технологий».
Зачем тут облако
Для любого сценария c резервным дата-центром характерны такие пожелания:
- Запуск приложений на резервной площадке за время меньшее, чем показатель RTO. Показатель выбирается таким, при котором финансовые потери от простоя выше стоимости внедрения катастрофоустойчивого решения.
- Возможность работы пользователей не только из основного офиса, но и из любого другого места. Полезная при масштабной аварии децентрализация.
- Данные на аварийной площадке должны быть актуальными (свежими). Тут мы приходим к RPO: логично, что если складская база восстановится на состояние «день до инвентаризации», то компания получит огромные убытки из-за неверной информации по остаткам.
- Резервный дата-центр должен иметь показатель доступности, приближенный к 100% в год. На практике это означает максимальное число девяток после запятой (99,0%, …, 99,999%). Чем выше показатель доступности, тем больше вложений потребуется.
RPO, RTO, ПВО, ККО
Допустимая точка восстановления (RPO) показывает отметку во времени, с которой можно восстановить данные. Например, если можно предоставить данные по состоянию за 4 часа до происшествия, то RPO будет равняться 4 часам. RPO определяет количество данных, которые могут быть потеряны при аварии.
RTO определяется по времени недоступности сервиса из-за возникшего сбоя. Фактически это время выполнения процедур Failover, которое необходимо для возобновления нормальной работы сервиса.
")
Наиболее ощутимы для бюджета второй и четвертый пункт, подразумевающие строительство или аренду ЦОД вне стен родной компании. Более того, потребуется не просто перевезти часть железа в соседнее здание, а обеспечить действительно независимый подвод WAN и должный уровень надежности серверного помещения и инфраструктуры. В общем, на этом этапе «отваливаются» многие заказчики.
Для частичного решения вопроса человечество когда-то придумало сдавать «юниты» в подготовленном ЦОД. А с приходом виртуализации построение инфраструктуры из сотен выделенных серверов требовало от провайдера неизмеримо меньших денежных вливаний. Как следствие — подобные услуги стали дешевле и для конечного заказчика. Фактически мы получаем IaaS, самую популярную разновидность корпоративного облака. Если же ваша инфраструктура уже работает в виртуальной среде, то подключить стороннюю резервную площадку на тех же технологиях достаточно просто и недорого.
Запасной аэродром из vSphere
Для любой системы с резервированием необходим некий сервис-дирижер, который бы обрабатывал события аварий и выполнял определенные действия. Коль скоро мы обсуждаем катастрофоустойчивое решение на базе vSphere, то таким сервисом будет vSphere SRM (Site Recovery Manager).
SRM (Site Recovery Manager) — это решение для автоматизации всего процесса восстановления VM на резервной площадке. Это не готовое DR-решение, а менеджер для координации сразу нескольких отдельных систем (гипервизоры, хранилища, сети).
Может возникнуть сомнение в целесообразности использования SRM, ведь многие приложения предлагают собственные механизмы отказоустойчивости. Вопрос в чем-то риторический, но основными доводами за SRM я бы назвал такие:
- Не все приложения в действительности предлагают рабочую схему резервирования. Есть огромное множество корпоративного ПО, которое ничего не знает о кластерах и какой-то там доступности. При этом свои функции выполняет, и выбрасывать его никто не собирается.
- SRM работает прозрачно для приложений. Теоретически можно использовать один и тот же подход к защите любого приложения. На практике все, конечно, несколько сложнее и не учитывать особенности сервисов не получается. Тем не менее администратор катастрофоустойчивого решения хотя бы будет оперировать понятными ему сущностями, не вдаваясь в особенности ОС и приложений внутри виртуальных машин.
- Затраты на поддержку систем резервирования каждого приложения могут и не окупаться туманными перспективами «правильного» переключения. Потому многие компании склоняются к более дешевому и универсальному варианту.
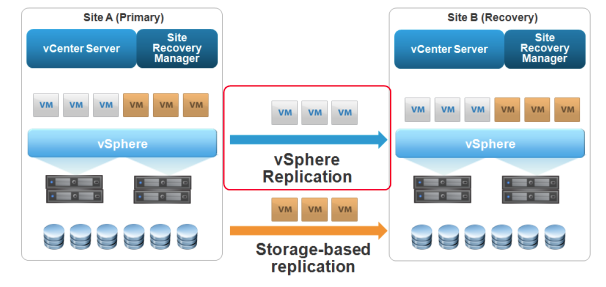
Схема работы vSphere SRM — две площадки с реплицированным хранилищем и сценариями переезда VM при нажатии «красной кнопки» администратором
На рисунке изображен типичный сценарий аварийной площадки средствами SRM Active-Passive. Есть два сайта, каждый содержит свой набор серверов ESXi с общим хранилищем и персональным vCenter. На картинке VM разделены на две группы приоритетов: для первой репликация виртуальных дисков происходит средствами vSphere Replication, для второй этим занимаются системы хранения (Storage-based replication). Такое разделение полезно, когда VM много, а места на СХД с собственной репликацией мало. Благодаря своеобразной балансировке трафика между аппаратной репликой и vSphere Replication, можно использовать в защите менее важных виртуальных машин более дешевые системы хранения. Схема довольно простая, хотя в арсенале SRM есть и другие варианты:
- Active-Passive. Вариант с рисунка, где второй сайт простаивает большую часть времени и включается в работу лишь при аварии основного.
- Схема N+1, где на некое множество активных сайтов приходится 1 резервный.
- Active-Active — схема, при которой оба сайта заняты делом и страхуют друг друга на случай аварии.
Любую из этих схем можно частично или полностью построить на базе облака, что позволит получить максимально дешево такие возможности:
- Failover и Failback одним нажатием. Сценарий аварийного восстановления заранее составляется и проверяется администратором, а при наступлении часа Х достаточно нажать «большую красную кнопку». О правильной перенастройке репликации позаботится сама SRM. В план также можно добавить очередность загрузки VM и правила смены IP-адресации, что полезно при наличии своих подсетей на удаленной площадке.
- Проверка работоспособности сценария «на лету». vSphere SRM может проверить, как отработает новый план восстановления, для чего выполнит предварительную репликацию с последующим переключением нагрузки на дублирующий сайт. От действительно аварийной ситуации тестирование отличается именно обязательно успешной репликацией — при ее сбое тест запущен не будет. В любом случае никакая информация не потеряется.
- Полигон для испытаний. Можно запустить копию «живых» виртуальных машин в изолированной среде для проверки предстоящих обновлений ПО или реорганизации инфраструктуры.
В таблице ниже вы найдете небольшое сравнение реализации DRS средствами корпоративных приложений и vSphere SRM. Разумеется, не на все вопросы есть прямой и точный ответ (для этого нужно рассматривать конкретные приложения), но табличка позволяет бросить на ситуацию взгляд с высоты и грубо прикинуть, что могло бы быть более интересным именно в вашей ситуации.
| vSphere SRM | Штатные возможности приложения | |
| Целостность данных | В общем случае SRM работает ниже уровня приложений или vmdk, что ограничивает возможности обеспечения консистентности данных | Поддержка родных функций консистентности (например, VSS) для файлов, БД и прочего |
| Сложность администрирования | Единый веб-портал управления виртуальной средой, общий подход для любых приложений | Отдельный инструмент управления приложения, не зависит от среды и наличия виртуализации. Требует специфических знаний для каждого приложения |
| Поддержка топологий DR | Active-Active Active-Passive N+1 (как Active-Passive, но пассивный сайт один на N активных) | Зависит от конкретного ПО. Типовой вариант Active-Passive |
| Автоматическое переключение на резервный сайт | Возможно с помощью скриптов, но не рекомендуется во избежание лишних «переключений» | Как правило, есть привязка к типу SAN. Стандартный вариант — FCiSCSI; довольно высокие требования к ширине канала |
| Требования к инфраструктуре | Возможна работа с любыми сетями и СХД. Несколько вариантов репликации с возможностью сжатия позволяют работать даже на не слишком быстрых каналах | Как правило, есть привязка к типу SAN. Стандартный вариант — FCiSCSI; довольно высокие требования к ширине канала |
Консистентность данных или приложения — обеспечение логической и физической целостности информации в хранилище приложения (файл, БД). Простой пример — состояние файловой системы ОС после отключения питания без предварительного завершения работы. Резко обрубленное электричество не оставило времени ОС корректно дописать данные из кэшей на диск и закрыть их, в результате имеем ошибки. То же самое с приложениями, которые могли банально не успеть скинуть часть содержимого оперативной памяти на диск.
Непростые вопросы репликации
Актуальная информация на обоих сайтах — самый важный компонент катастрофоустойчивого решения. От стабильной синхронизации хранилищ напрямую зависят показатели RPO, потому остановимся подробнее на репликации.
vSphere Replication поддерживает два вида синхронизации:
- Собственный механизм vSphere Replica. Это репликация на уровне гипервизора ESXi, не зависящая от типа и идентичности СХД на всех сайтах. Доступна в редакции vSphere Essentials Plus и выше. Отличительная особенность — возможность перегонять данные между разными типами К примеру, наличие VSAN на основной площадке и DAS на резервной — не помеха для этого механизма. Но следует помнить о техническом ограничении в 15 мин RPO — при миграции площадки на резервное хранилище 15 мин работы будут потеряны.
- Репликация на уровне систем хранения. Более эффективный механизм, при котором весь процесс синхронизации передан устройствам хранения. Специфика подхода диктует некоторые требования к хранилищам — полный список совместимых продуктов можно посмотреть на странице Compatibility Matrix. Рекомендуется использовать идентичные СХД с активированными средствами репликации в каждом сайте. Раньше это удовольствие было довольно дорогим, но сейчас доступно даже в бюджетных продуктах вроде HP MSA (P2000). Минимальное RPO аппаратной репликации — около пары минут, что вполне вписывается в требования критичного приложения.
Что из этого выбрать? Хороший вопрос, но в общем случае рекомендуется гибридный вариант. В нем вы выделяете datastore с аппаратной репликацией наиболее важных VM, а все остальные защищаете механизмом vSphere Replica, который допускает работу с более дешевыми СХД. Приятным бонусом от устройств с аппаратной репликацией будут также фирменные технологии снэпшотов, теневые тома и прочие полезности. В связи с популярностью систем хранения NetApp на отечественном рынке, рассмотрим именно их в качестве основного хранилища для DRS.
NetApp SnapMirror
Это и есть встроенный механизм репликации в массивах NetApp. Кроме привычных синхронной и асинхронной репликации, SnapMirror предлагает несколько интересных особенностей:
- Работа по IP-каналу. Может быть полезно при отсутствии волокна до облачного дата-центра или на первых порах создания резервной площадки.
- Поддержка синхронной, асинхронной и полу-синхронной репликации. Последнее работает так: пытаемся работать синхронно и если не успеваем, то переходим на асинхрон. Переходим обратно на синхрон, когда догоним исходную систему по состоянию. Очень полезная вещь для DR на быстрых, но не очень стабильных каналах.
- Для своей работы SnapMirror использует невидимые пользователю технические снэпшоты, что позволяет передавать небольшой объем изменений без лишних сложностей и нагрузки на СХД.
- Передаваемые блоки сжимаются, что ускоряет репликацию при прочих равных.
- В процессе сохраняется эффект дедупликации и сделанные на источнике снимки.
FlexClone
В описании SRM я упоминал о возможности использовать резервный сайт для чего-то полезного в быту. Например, для тестирования масштабных изменений на серверах. Фактически SRM создает изолированную лабораторию с собственным LUN, на котором уже размещены копии реальных данных. Для того чтобы все это красиво работало, NetApp предлагает необходимый для создания лаборатории FlexClone.

Идея FlexClone в том, чтобы мгновенно создавать копию тома без копирования реальных данных. Просто создается копия-пустышка со ссылкой на исходную информацию «живого» тома. Если же потребуется что-то дописать в клонированный раздел, то для этого используется специальная область.
При запуске сценария тестовой лаборатории SRM использует такую возможность NetApp для получения раздела с независимой копией данных. В итоге получаем следующее:
- Том клонируется мгновенно, так как не происходит «перетасовка» данных.
- Изменения на клоне пишутся в отдельную дисковую область.
- Копия тома занимает на массиве объем, равный сумме изменений. То есть если клонировать раздел в 10 Тб и изменить в полученной копии 100 Мб, то весь клон в реальности будет весить эти самые 100 Мб. Особенно заметна экономия места при создании сразу нескольких клонов для разных целей или пользователей.

На дисках клон займет ровно столько места, на сколько потянут Write-изменения
Таким образом, для организации полноценного полигона перед установкой новой версии MS Exchange всего лишь потребуется сделать следующее:
- Организовать реплику данных в облачном дата-центре. Делается это один раз при внедрении DR-решения.
- С помощью SRM запустить сценарий организации лаборатории, включающий создание FlexClone на резервной площадке.
Согласитесь, это гораздо интереснее ручного восстановления резервных копий VM на виртуальных машинах стенда с самостоятельной настройкой сети.
Вообще у NetApp много интересных технологий для работы со снимками и копиями томов, но не все они вписываются в тему этой статьи.
Что ж, пора подводить итоги. Мы обсудили преимущества работы с IaaS-облаком в качестве резервной площадки и оценили его гибкость. При использовании vSphere SRM и современных систем хранения катастрофоустойчивые системы уже не выглядят чем-то «для избранных». Вне зависимости от возможностей вашей сети хранения и уровня надежности дата-центра, благодаря облачным услугам можно застраховать бизнес организации от серьезных потерь.
Но лучше один раз попробовать, чем много раз прочесть, как все это красиво, верно? Потому напоминаю про наш тестовый полигон, где вы можете оценить возможности облачной vSphere и опробовать интересующие сценарии организации резервной площадки в облаке . Все, что в первую очередь вас заинтересует при построении собственного DR-решения, мы обсудили. О реализации конкретных сценариев речь пойдет в следующих материалах.


