Обусловливается все выше сказанное реалиями современного мира, который не стоит на месте: работают банки, торговые и промышленные комплексы, производственные и прочие компании. Всем им нужны инструменты, функциональные возможности которых позволяют получить востребованную аналитику в реальный момент времени.
Накопленные значительные объемы данных могут дать массу полезной информации. Банки, к примеру, анализируют миллионы записей в месяц, оценивая кривые спроса, процентные ставки, движение денежных средств, что позволяет решать одну из задач поиска идеальной ставки для привлечения как можно большего количества средств и минимизации расходов. Авиакомпании, в свою очередь, могут анализировать информацию о самых популярных и загруженных маршрутах, оперативно вводя дополнительные перелеты, тем самым сокращая затраты на техническое обслуживание и на управление оборудованием.
Или другой пример: гонки «Формула-1». Перед тем как принять участие в соревнованиях спортивных автомобилей на скорость, проводятся тестовые заезды. На каждый болид при этом устанавливают более 150 электронных сенсоров, расположенных по всему корпусу. Данные этих сенсоров- жизненно важная информация, позволяющая постоянно мониторить работоспособность всех компонентов и агрегатов гоночных автомобилей. В совокупности датчики одного болида генерируют около 1 Гб данных за заезд, а за три дня соревнований до 3 Тб. Данные содержат значения расположения каждой из машин на треке, скорости болидов, режимов работы коробки передач, оборотов двигателя, величины давления в тормозной системе, а также показателей давления технических жидкостей и воздуха в шинах.
С помощью этих данных можно получить сводную картинку технического состояния автомобиля и зафиксировать сигналы о неисправностях. К концу каждого сезона «Формулы-1», состоящего из множества гран-при, накапливаются терабайты бесценной информации, от корректного анализа которой зависит успех команды. И данный пример подтверждается фактами использования конкретного решения, а именно: анализ больших объемов данных команды McLaren в сезоне 2014 гонок «Формула-1» был возложен на технологию SAP HANA.
Если раньше клиент был доволен использованием традиционных СУБД с хранением данных на стабильных носителях, то теперь все чаще и чаще взгляд падает на решения, обеспечивающие хранение, расчет и обработку данных непосредственно в оперативной памяти в режиме реального времени. Данный подход согласно критерию оценки высокой производительности дает значительный выигрыш, обуславливаясь непосредственно тем, что обработка данных в оперативной памяти протекает значительно быстрее, чем при обращении к файловой подсистеме.
В данной статье мы остановимся на программно-аппаратном комплексе SAP HANA , рассмотрев его в разрезе виртуализации на базе VMware. И в рамках данного повествования ответим на вопросы, которые у Вас, уважаемые читатели, могут возникнуть: почему SAP HANA, почему в облаке, какие принципиальные возможности и функциональные особенности дает выбранное решение, каковы методики расчета облачных мощностей под хостинг SAP HANA?
Почему SAP HANA?
И так, поехали. Для начала поговорим о самой технологии SAP HANA , которую довольно часто именуют технологией вычислений «in memory», представляющую платформу для организации работы в реальном режиме времени.
Что значит «HANA»? Компания SAP дает следующую расшифровку: High Performance Analytical Appliance, что означает высокопроизводительный инструмент для аналитики. Решение объединяет в себе как аналитические инструменты, так и средства обработки транзакций с крупными объемами данных. Как пример, SAP HANA позволяет выполнять мониторинг социальных сетей с возможностью автоматического считывания показаний счетчиков через Интернет. На сегодняшний день решение SAP HANA можно смело назвать стандартом де-факто, предлагающим следующие конкурентные преимущества:
- Анализ крупных массивов данных, который происходит в тысячи раз быстрее каких-либо других методов анализа;
- Мгновенный, удобный доступ к данным из основной памяти;
- Быстрая параллельная обработка данных и мгновенные вычисления;
- Репликация данных из бизнес-систем практически без задержки;
- Снижение затрат и повышение гибкости благодаря упрощенному ИТ-ландшафту.
Как говорилось ранее, обработка большинства данных в SAP HANA выполняется в оперативной памяти, при этом используется сочетание хранения данных в построчном и поколоночном виде с применением соответствующих алгоритмов сжатия. При такой гибридной реализации требуется значительно меньший объем оперативной памяти по сравнению с традиционным хранением, что также является техническим преимуществом.
База данных в SAP HANA, как правило, расположена на различных типах хранилищ, которые отличаются скоростью доступа к данным. Давайте рассмотрим эти типы хранилищ:
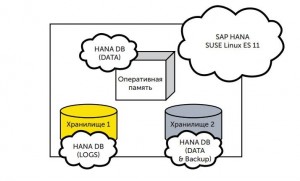
- Оперативная память (RAM) ос
Используется для хранения базы данных пле первоначальной загрузки с постоянного хранилища - Хранилище 1 (высокопроизводительное)
Используется в процессе работы базы данных для хранения файлов-журналов (логов) - Хранилище 2 (низко производительное)
Используется для хранения резервных копий, дата файлов базы данных, данных приложения и операционной системы.
Таким образом, можно смело утверждать, что технология SAP HANA заменяет сложный, дорогостоящий механизм сбора и анализа данных, обеспечивая гибкий подход к их обработке в реальный момент времени. Помимо всего прочего SAP HANA может работать с любыми источниками данных, начиная от систем SAP ERP до составленных таблиц в Excel.
Почему в облаке?
В последнее время компания SAP часто называет себя облачной, а ведь это уже не будущее, а настоящее. Подтверждается вышесказанное серьезными стратегическими вложениями со стороны SAP, охватывающими такие направления как мобильность, большие данные и облака. При этом отмечается, что «первым и единственным гипервизором для продуктивного использования SAP HANA в облаке является продукт VMware». В дополнение обратимся к комментарию члена правления SAP AG Бернда Лёйкерта. По его словам: «SAP HANA лидирует на рынке как корпоративная платформа реального времени, позволяющая упрощать ИТ и внедрять прорывные для бизнеса инновации. Вместе с VMware мы помогаем клиентам разместить критически важные приложения на базе SAP HANA в виртуальных средах, ускоряя переход к программно-определяемым ЦОД и, в конечном счете, к облакам».
Облачные преимущества
Одним из ключевых преимуществ виртуализации SAP HANA с помощью решений VMware является возможность работы с несколько меньшими экземплярами HANA на одном физическом сервере. Это значит, что аппаратный комплекс для HANA теперь не обязательно привязывать к одному экземпляру СУБД, он может одновременно поддерживать несколько виртуальных экземпляров HANA, что обеспечивает заказчику больше гибкости в использовании имеющихся ресурсов. Поддержка виртуального окружения VMware vSphere 5.5 со стороны SAP HANA поможет заказчикам упрощать и ускорять процедуры центров обработки данных.
Также стоит отметить, что благодаря комбинации производительности SAP HANA и ресурсов основного компонента VMware vCloud Suite - VMware vSphere 5.5, клиенты получают возможность упростить свой центр обработки данных, обеспечивая наилучший уровень сервиса, а также снижение совокупной стоимости владения инфраструктурой.
При этом пользователи SAP HANA получат преимущества от более широкого использования инфраструктуры, гибкости и производительности в рамках нового комбинированного решения:
- SAP HANA на vSphere предлагается заказчикам на базе сертифицированных устройств SAP HANA или специальном интегрированном оборудовании ЦОД, разработанном специально для SAP HANA;
- Поддерживается до 1 Тбайт памяти и до 32 физических ядер (64 виртуальных ядра) для одной инсталляции на VMware vSphere;
- SAP HANA поддерживает возможности VMware vSphere по управлению клиентскими системами, включая vMotion®, Distributed Resource Scheduler™ (DRS) и VMware High Availability (HA);
Функциональные особенности и возможности SAP HANA в облаках
Виртуализированное решение SAP HANA на базе VMware дает заказчику следующие функциональные особенности и возможности:
- Значительное сокращение времени развертывания HANA (создание нового узла SAP HANA становится простым заданием, выполняемым средствами VMware с использованием технологии копирования и клонирования);
- Возможность оперативной миграции виртуальных экземпляров HANA посредством vMotion
(эталонные тесты показали следующие цифры: интенсивно нагруженный виртуальный экземпляр SAP HANA с 512 Гб памяти можно клонировать и копировать из одного дата центра в другой с помощью vMotion примерно за 10 минут).
Методика расчета необходимых облачных мощностей под хостинг SAP HANA
Теперь давайте остановимся на следующем вопросе: как рассчитываются облачные мощности под хостинг SAP HANA? Несмотря на то, что многие вендоры предлагают свои протестированные под определенные задачи конфигурации для SAP HANA с предустановленным аппаратным и программным обеспечением, готовым для внедрения в корпоративную ИТ инфраструктуру, попробуем сами вникнуть в формулы и расчеты. Для ответа на выше озвученный вопрос рассмотрим наилучшие практики и рекомендации.

С чего начать? В первую очередь необходимо понимание, что одновременное выполнение множества задач увеличивает требования к производительности IT-инфраструктуры. И если облачная площадка, обеспечивающая работу систем на базе SAP HANA, будет недостаточно производительна в силу неверно выделенных под нее ресурсов, это породит ряд значительных проблем по части предоставления адекватного уровня сервиса.
Замечание: При расчете мощностей под SAP HANA в облаке особое внимание следует уделять общей памяти. Ее размер определяется количеством данных, которые в ней должны быть сохранены. А затем, отталкиваясь от определенных значений, вычислять мощности других ресурсов: дисковой подсистемы и процессора.
Компания SAP дает ряд рекомендуемых конфигураций под SAP HANA, представляя процесс расчета мощностей так, как если бы Вы выбирали для себя соответствующий размер футболки.
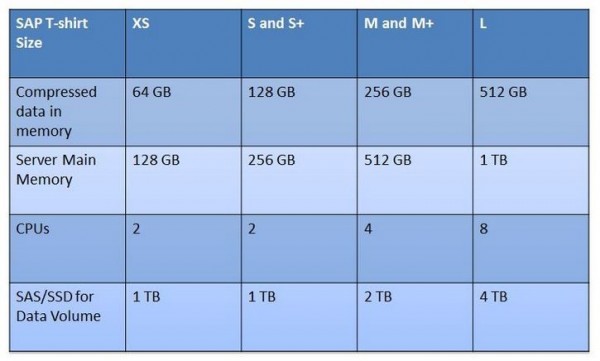
Таблица 1. Типовая конфигурация под SAP HANA от компании SAP
Размеры футболок S и S+ отличаются незначительно, точно так же как и M с M+. Если футболка размера S Вам все же окажется мала, ее можно поменять на М. Манипуляции с футболкой размера М аналогичны, ее всегда можно поменять на L. Так же поступаем и с ресурсами: если выделенных ресурсов мало, всегда есть возможность их нарастить. Указанные в таблице «размеры» являются наиболее популярными и большинство бизнес задач на базе SAP HANA вполне впишутся в представленные лимиты.
Пояснение к использованию таблицы:
Помните, что общее количество оперативной памяти всегда округляется до ближайшего значения в таблице. Если общее количество памяти RAM выбрано как 400 Gb – это футболка размера «М and M+», а значит, рекомендуется использовать 4 процессора и дисковую подсистему в 2 Tb.
В дополнении к «стандартным размерам футболок», которые применяются почти во всех случаях с SAP HANA, существуют конфигурации, являющиеся специфическими.
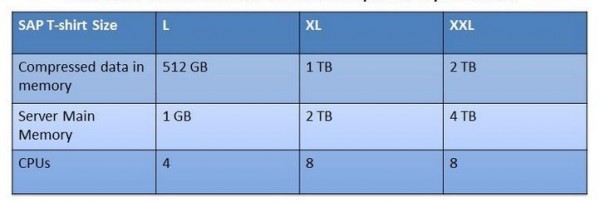
Таблица 2. Нетиповая конфигурация под SAP HANA от компании SAP
Данная «специфика» заключается в использовании приложений SAP Business Suite на базе SAP HANA. При этом нагрузка, обусловленная использованием данных приложений, может иметь различные характеристики, сопровождаясь меньшей нагрузкой на процессор и более интенсивным использованием оперативной памяти.
И так, приступим непосредственно к расчетам.
Расчет ресурсов RAM
Имея перед собой такую задачу, как вычисление ресурсов RAM, надо понимать, что требования к общей памяти делятся на две составляющие:
- расчет статической (RAM static) памяти
Статический объем памяти, используемый HANA, определяется количеством данных, которые должны быть сохранены в памяти. - расчет динамической (RAM Dynamic) памяти
Дополнительная оперативная память потребуется для объектов, которые создаются динамически, при загрузке новых данных или выполнении запросов.
И как рекомендует SAP: резервируйте столько динамической памяти, сколько и статической. При этом вычисление общего объема памяти (RAM total) будет складываться из статической памяти, умноженной на 2.
RAM dynamic= RAM static
RAM total =RAM dynamic + RAM static=2 * RAM static
Расчет ресурсов дисковой подсистемы (HDD)
При вычислении ресурсов дисковой подсистемы следует обратить внимание на следующие особенности:
Заметка: Помните, что результаты первичного определения параметров оборудования необходимо постоянно проверять, поскольку внезапный рост объема данных может привести к переносу данных из памяти в постоянное хранилище данных, а это повлечет за собой значительную потерю производительности.
- Уровень «сохраняемости» (том данных)
Изменяемый набор данных с базы данных «in memory» периодически копируется на «том данных» с целью сохранения информации в случае форс-мажорных обстоятельств. Или как говорилось ранее в статье: том данных - это низко производительное хранилище, которое, еще раз повторимся, хранит резервные копии, дата файлы базы данных, данные приложения и операционной системы.Объем тома вычисляется по формуле:
Disk persistence = 4 * RAM total - Диск журналов (том журналов)
Том журналов сохраняет информацию об изменениях базы данных, с целью восстановления после перезагрузки ее последнего сохраненного состояния. Такой том или хранилище называют высокопроизводительным.Объем тома определяется по формуле:
Disk Log = RAM total
Disk total= Disk persistence + Disk Log
Заметка: Помните, что результаты первичного определения параметров оборудования необходимо постоянно проверять, поскольку внезапный рост объема данных может привести к переносу данных из памяти в постоянное хранилище данных, а это повлечет за собой значительную потерю производительности.
Расчет ресурсов CPU
Если ожидается рост количества пользователей, работающих с относительно небольшим объемом данных, рекомендуется увеличить объем оперативной памяти с наращиванием при этом мощностей процессора. Расчет ресурсов процессора напрямую зависит от количества пользователей. SAP HANA поддерживает 300 SAPS для каждого одновременно активного пользователя. В зависимости от серверной модели SAP HANA может поддерживать около 60-65 одновременно активных пользователей на 1 CPU.
CPU: 300 SAPS/ Активный пользователь, где SAPS (SAP Application Performance Standard) - единица измерения, описывающая производительность сконфигурированной системы SAP.
Более подробную информацию о SAPS Вы можете найти по ссылкам:
Что бы свести к минимуму сложность вычислений требуемых ресурсов под решения SAP HANA и облегчить планирование инфраструктуры, компания SAP предлагает инструмент Quick Sizer. Он поможет вычислить необходимые ресурсы RAM, HDD, CPU, а так же количество операций ввода/вывода (IOPS).
На картинке ниже Вы видите отображенный результат значений ресурсов посредством инструмента Quick Sizer. При этом значения параметров CPU, HDD предоставляются в формате «размеров футболки» знакомой нам модели SAP T-shirt size.

Что бы воспользоваться данным инструментом пройдите по ссылке.
Примечание: Для скачивания Quick Sizer необходимо наличие аккаунта в SAP service market place.
Так же рекомендуем Вам воспользоваться результатами тестов SAP Standard Application Benchmarks. Именно тут представлены примеры стандартных прикладных тестов, которые помогут Вам найти подходящую аппаратную конфигурацию для решения своих ИТ задач.

Пример расчета
Для бОльшего понимания пользы SAP HANA рассмотрим сценарий применения SAP HANA и подберем ресурсы под облачный хостинг.
Некая букмекерская компания «Х» обладает 60 GB информации по игрокам, матчам, забитым голам и другой спортивной статистикой. Для того, чтобы предоставить клиентам возможность через web-сайт осуществлять выборки любой сложности и по любому количеству параметров, требуется аналитическая система, которую клиент хочет расположить в «облаке».
Что предложить клиенту в качестве возможной «облачной» конфигурации?
В дано: мы имеем 60 GB данных, от этого и будем отталкиваться.
Поскольку RAM total =RAM dynamic + RAM static=2 * RAM static
RAM total=2* 60=120 GB
Для вычисления объемов дисковой подсистемы вспомним формулы:
Disk persistence = 4 * RAM total
Disk Log = RAM total
Disk total= Disk persistence + Disk Log
Таким образом, для дисковой подсистемы необходимо следующее пространство:
Disk total = 4*120 + 120 = 600 GB
Для выбора количества процессоров воспользуемся Таблицей 1. Типовая конфигурация под SAP HANA от компании SAP, приведенной ранее в статье. Количество используемой оперативной памяти, согласно полученным расчетам равно 120 GB, а это значит, что под наше решение подходит «размер XS» рассматриваемой таблицы. Поэтому количество процессоров под текущую задачу может быть равным 2.
Согласно выше озвученным расчетам и данным в Таблице 1. Типовой конфигурации под SAP HANA от компании SAP , можем воспользоваться следующей конфигурацией под виртуальную машину:
| Ресурс | Количество |
| vCPU | 2 |
| RAM | 128 GB |
| Disk total | 1 TB |
Таким образом, на примере рассмотренных ранее формул и практического примера, Вы сможете рассчитать необходимые ресурсы для размещения SAP HANA в облаке IaaS-провайдера.
Подводя итоги, мы можем уверенно сказать, что виртуализация VMware уверенно шагает вперед, и на сегодняшний день ни у кого не остается сомнений в том, что виртуальная инфраструктура с успехом справляется с обслуживанием высоконагруженных баз данных и приложений, которые без потери производительности стабильно работают как в частных, так и в публичных виртуализированных средах.


